etence.ocr: распознавание и обработка документов
Извлекаем данные из скан-образов, настраиваем обработку под типы документов компании и встраиваем результат в действующий контур через интерфейс или API.

Когда подходит etence.ocr
Решение полезно компаниям, которые регулярно получают сканы, фотографии или пакеты документов и хотят быстрее переводить их в проверяемые структурированные данные. Конфигурация подбирается под типы документов, качество входящих изображений, правила проверки и способы передачи результата во внутренние системы.
Как работает решение
Решение принимает от сотрудника или по API скан документа
С помощью OCR, нейронных сетей и собственных алгоритмов из документов извлекаются данные
Полученные данные в структурированном виде становятся доступны в интерфейсе или передаются по API
Кому подходит etence.ocr
Решение уместно там, где поток документов уже влияет на скорость обслуживания, нагрузку бэк-офиса или качество данных в CRM, ERP, документообороте и отраслевых системах.
Когда клиенты или сотрудники регулярно передают документы, которые нужно быстро проверить и перенести в систему.
Когда ручной ввод данных замедляет обработку и создаёт риск ошибок в типовых операциях.
Когда результаты распознавания нужно передавать в CRM, ERP, документооборот или отраслевую систему.
Какие сценарии закрывает решение

Анализ и обработка входящего потока документов (в том числе документов без наличия формализованной структуры)

Проверка качества и правильности заполнения входящего потока документов

Классификация документов

Извлечение данных на основе технологий машинного обучения

Проверка корректности полученной информации

Генерация производной информации и передача требуемой информации во внешние системы
Какие документы можно распознавать
Состав поддерживаемых документов настраивается под проект: от типовых удостоверяющих и бухгалтерских документов до договоров, спецификаций и неструктурированных материалов.
Документы физического лица
- Паспорт
- СНИЛС, ИНН
- Военный билет
- Заграничный паспорт РФ
- Водительское удостоверение, СТС, ПТС
- Вид на жительство
- ID иностранных граждан
- Свидетельство о рождении, браке и разводе
- Трудовая книжка
- Справка 2-НДФЛ или по форме банка
Бухгалтерские документы
- УПД
- Счёт-фактура
- Товарная накладная
- Счёт, акт и чек
Неструктурированные
- Договор
- Спецификации
- Письма


Где применяется распознавание документов
etence.ocr можно внедрять в разных отраслях, если есть повторяемый поток документов, требования к скорости обработки и необходимость передавать результат дальше по процессу.

Банки и финансовые организации

Страховые компании

Такси и каршеринг

Бухгалтерские и аудиторские службы

Туризм

IT-платформы

Недвижимость

Юридические компании

Образовательные организации
Что это даёт бизнесу
Документы проходят первичное распознавание и попадают к сотруднику уже в структурированном виде.
Операторы тратят меньше времени на перенос данных и повторные проверки типовых полей.
Результаты можно передавать через API или использовать в рабочем интерфейсе сотрудников.
Сотрудник видит спорные места и может проверить данные до передачи в следующий процесс.
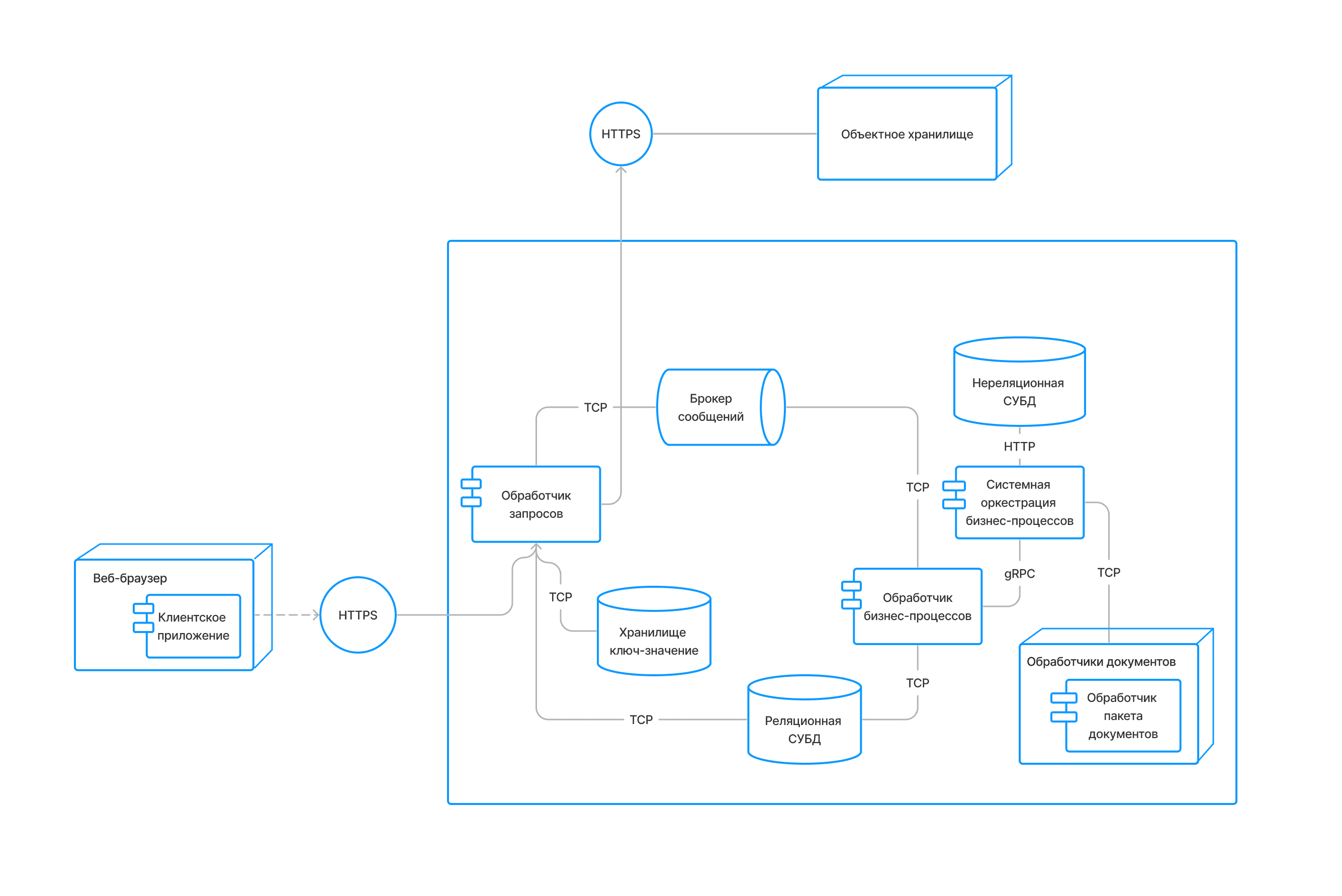
Из чего состоит решение
Интерфейс сотрудника
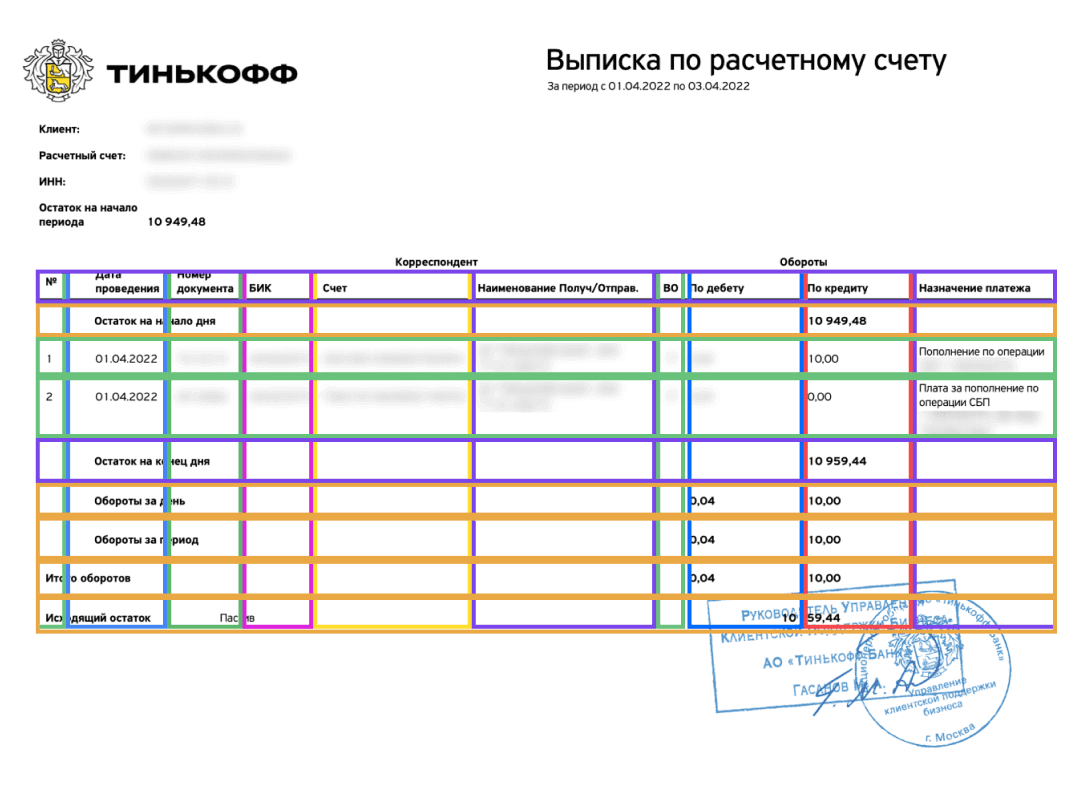
Обработка изображений
Управление бизнес-процессами
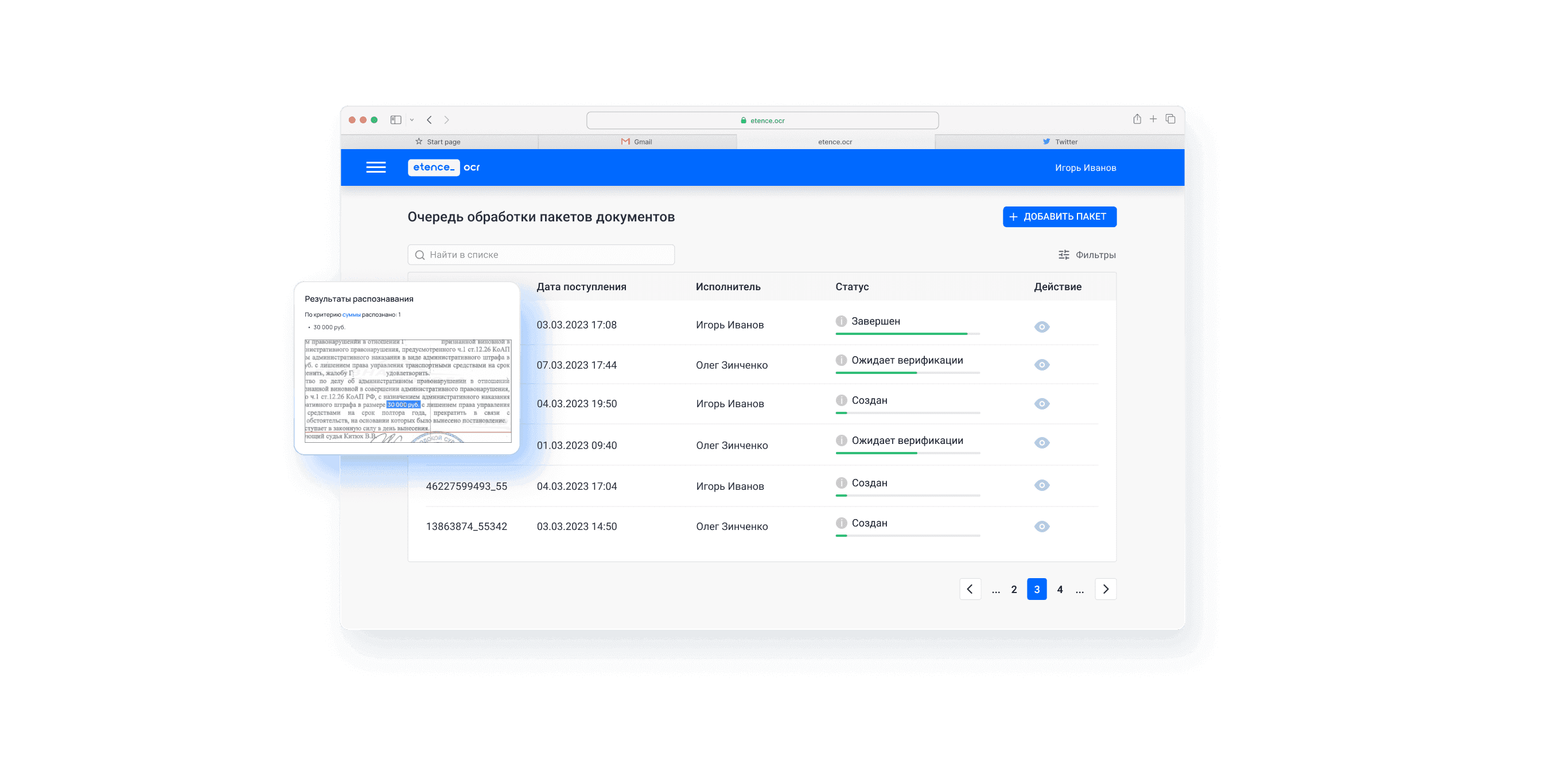
Очередь обработки пакетов документов
Интерфейс сотрудника
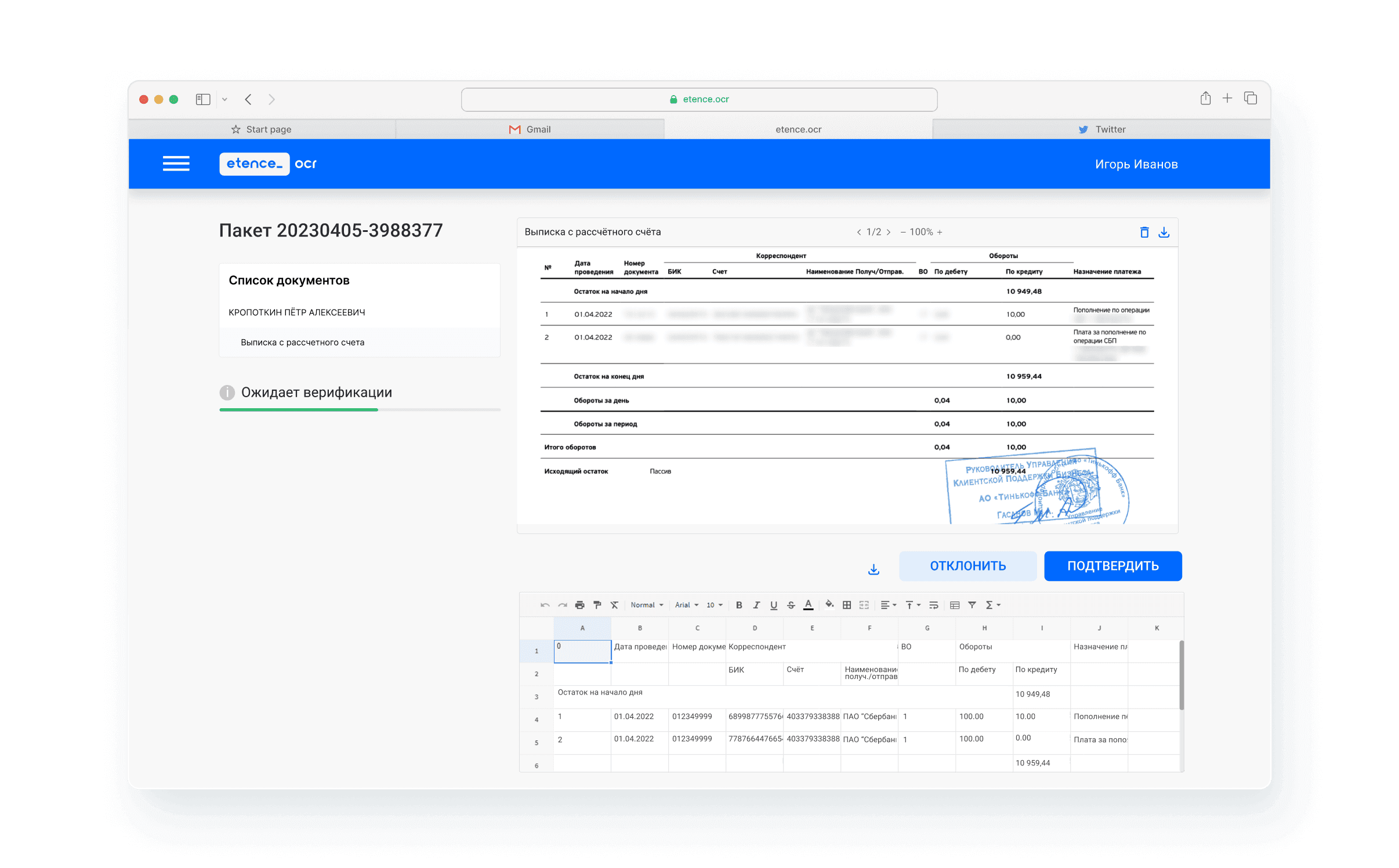
Интерфейс помогает работать с пакетами документов, проверять результаты распознавания и выполнять административные настройки решения.
Фильтрация
Для взаимодействия с большим набором обрабатываемых пакетов пользователям предоставляется функционал фильтрации, сортировки и полнотекстового поиска (включающего в себя сквозной поиск по распознанному со скан-изображений тексту) по всем загруженным в Систему пакетам документов.
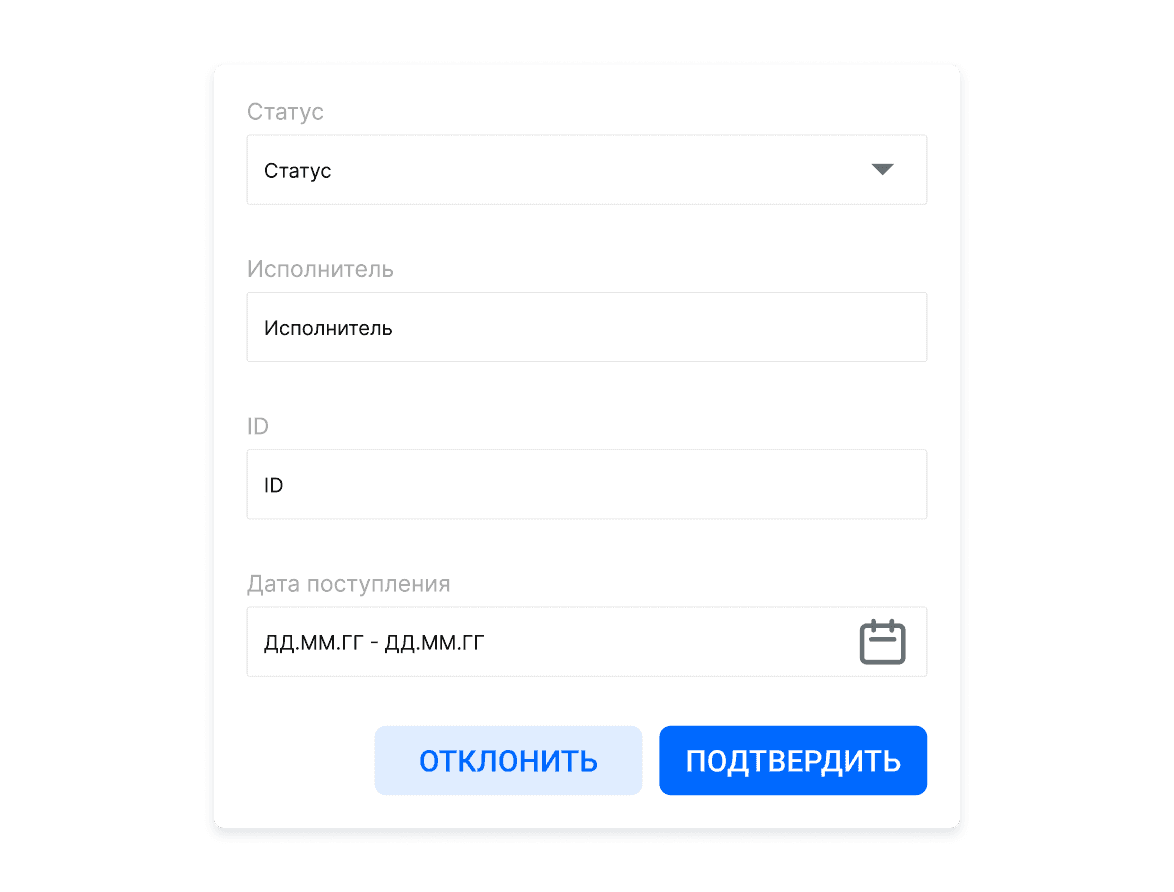
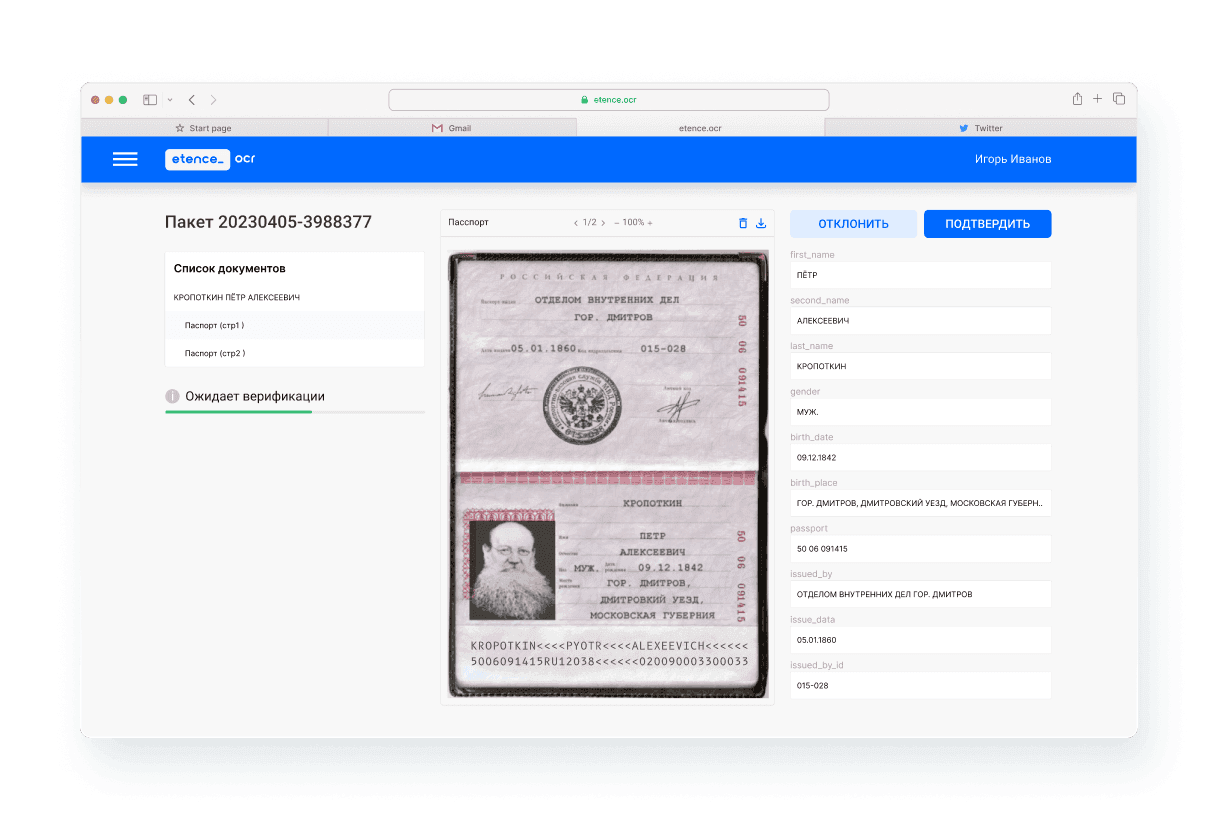
Контроль данных пользователем
Обработанные Системой документы могут быть проверены пользователями Системы на соответствие обработки с требуемыми метриками качества извлечения информации и преобразования скан-изображений.
При нахождении несоответствий, документы могут быть отмечены специальными маркерами, влияющими на дальнейшие стадии бизнес-процесса обработки пакета.
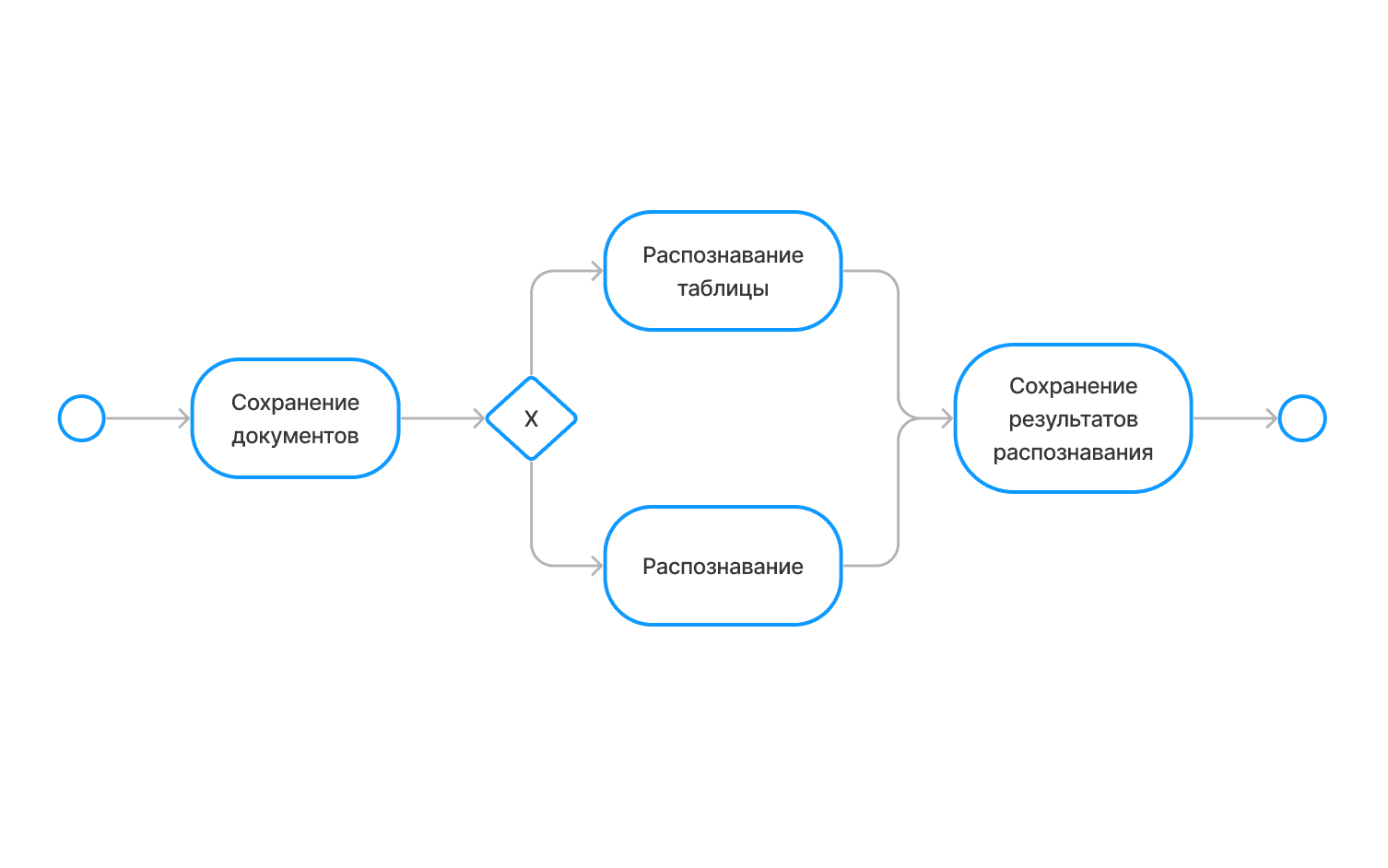
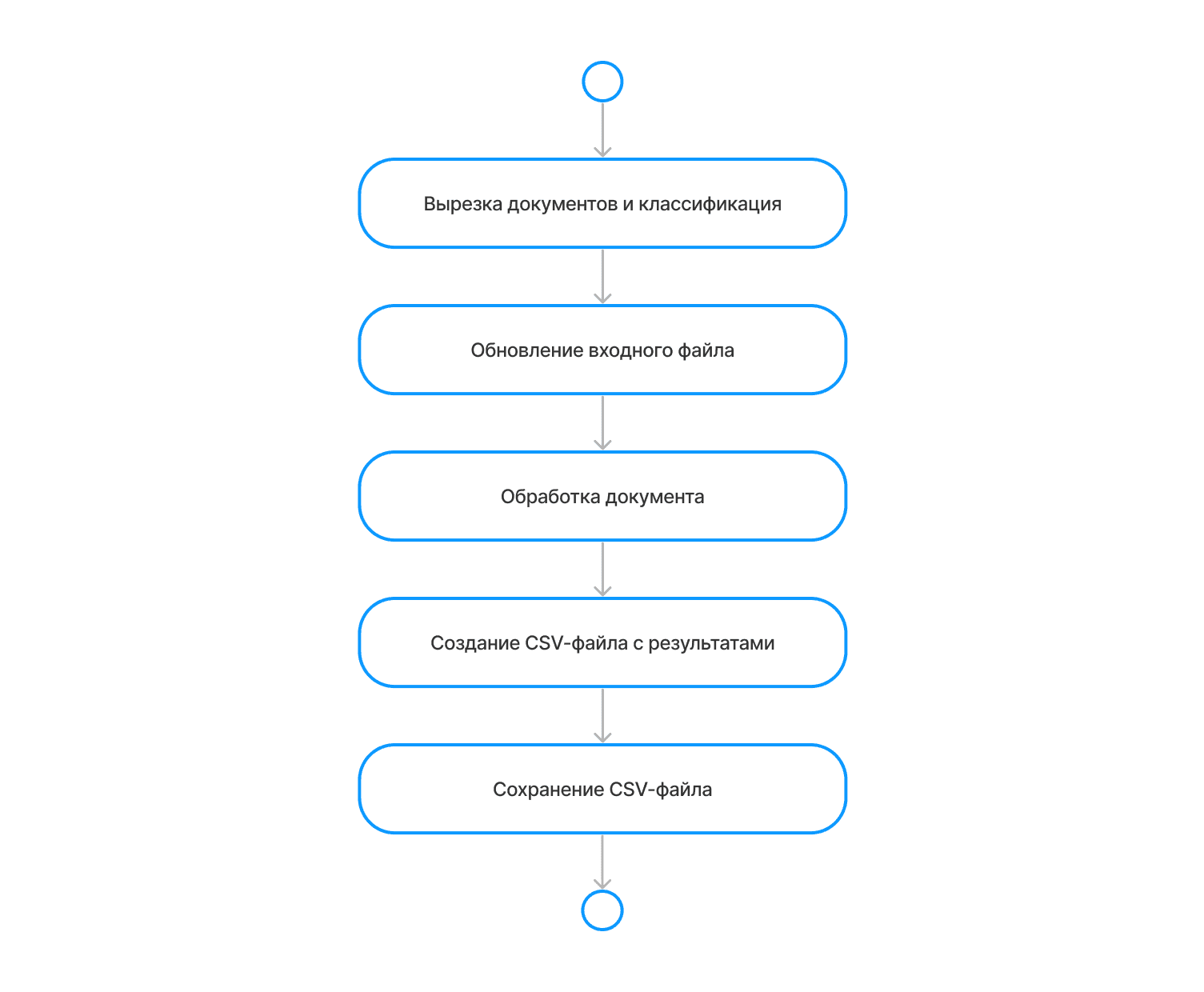
Обработка документов
Этот слой отвечает за предобработку изображений, классификацию, распознавание текста и извлечение нужных полей.
Пакеты документов попадают в очередь обработки. С учётом заданных приоритетов решение выполняет следующие задачи:
Улучшение исходных изображений: увеличение контраста, яркости, подавление шума
Обрезка и поворот изображений
Разбиение многостраничных документов на одностраничные
Разбиение изображений, содержащих несколько документов, на отдельные документы
Классификация каждого полученного документа согласно словарю предопределенных типов документов
Извлечение текстовых данных с изображения
Извлечение ключевых слов, требуемых для конкретного типа документов согласно словарю
Наложение на исходные скан-изображения текстового слоя
Управление бизнес-процессами
Сценарии обработки настраиваются под входные данные, события, правила проверки и передачу результатов во внешние системы.
Настройка входных данных
- Автоматическое получение данных из внешних систем
- Получение данных из внешних систем по заданному расписанию
- Получение данных из внешних систем при наступлении событий во внешней системе
- Ручное добавление данных
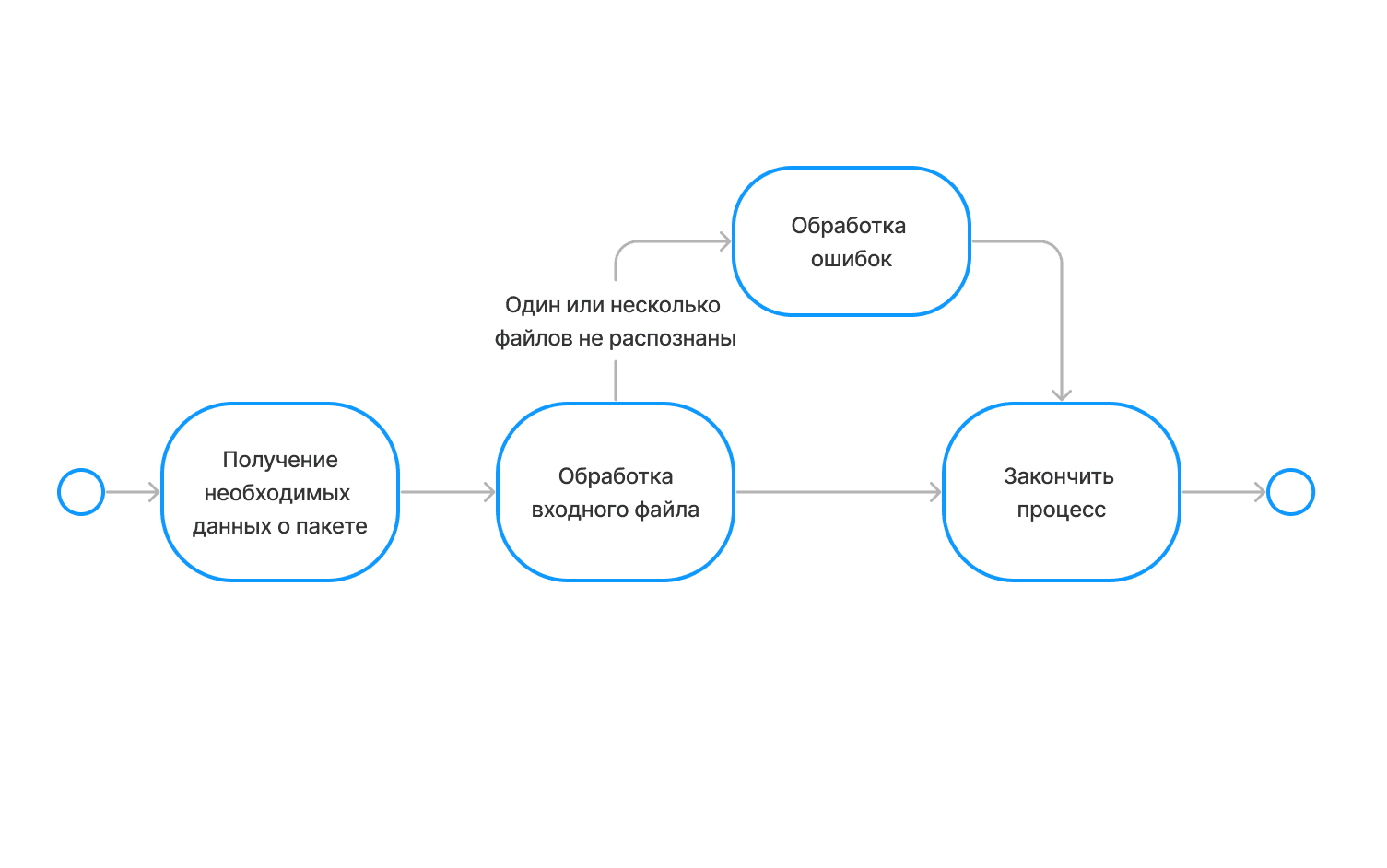
Настройка событий обработки пакетов
- Отправка сообщений о наступлении события во внешние системы
- Отправка e-mail уведомлений о наступлении событий
- Автоматическое изменение пакетов документов при наступлении событий
- Отправка промежуточной информации во внешние системы
- Настройка необходимости ручной верификации обработки пакетов
Настройка результатов обработки пакетов документов
- Автоматическая отправка результатов после окончания обработки
- Рассылка e-mail оповещений с результатами обработки
- Ручная обработка результатов
Очередь обработки пакетов документов
Очередь помогает управлять приоритетами, нагрузкой и статусами обработки в режиме реального времени.
- выбор приоритетных пакетов документов;
- балансировка нагрузки;
- синхронизация параллельных процессов;
- контроль статусов и результатов обработки.
Технический контур
Серверная часть решения
Использует технологии, которые можно развернуть в облачной инфраструктуре Kubernetes / Docker:
- PostgreSQL;
- Elasticsearch;
- RabbitMQ;
- Zeebe;
- Minio (S3);
- Redis.
Клиентская часть решения
Для работы с клиентской частью нужен браузер на рабочей станции.
Что дальше
Если нужно оценить, какие документы стоит распознавать в первую очередь и как встроить обработку в существующий процесс, можно обсудить задачу с командой RB Tech. Мы поможем уточнить входной поток, качество данных, интеграции и границы пилотного внедрения.